
Dennis Cokely Parallel Corpus: Data and Materials
Parallel corpora
Parallel corpora are research databases of translations in which the relationship between units in the original text are represented with the corresponding units in the translation. Parallel corpora are also called translation or bilingual corpora depending on the specific type of data that they represent. Parallel corpora stand in contrast with monolingual corpora. Because all corpora are in an electronic text format, they can be searched, processed, and visualized with software tools. Parallel corpora are data that can be used to answer research and applied educational questions within the field of translation or interpretation studies. Different methods and tools can be used to analyze, describe, and learn from the translation data.
Parallel corpora based on economically and politically dominant language pairs are widely available to interested researchers. Many minority languages, such as the 100+ signed languages used around the world, do not have language technology resources such as corpora. In order to build a corpus for any language, there needs to be a way to represent the language in a database. This entails the use of electronic text based on the standard writing system of the language. However, if a language does not have a writing system, it is challenging to find a suitable electronic representation that can be automatically searched and processed in a database.
Corpora in Signed Languages
An emerging approach for developing corpora for signed languages is to utilize an ID-Gloss system based on the majority writing system of the country in which the sign language is used. For example, different systems of English-based ID-Glosses represent the mutually unintelligible signed languages used in the UK and the US—British Sign Language and American Sign Language respectively. An ID-Gloss is a unique text label for each sign that consistently represents all instances of the same sign across the corpus. ID-Glosses are maintained in a lexical database as a controlled vocabulary for each corpus project. Software tools such as ELAN can maintain the time-based relationship between the video recording of signed language discourse and the ID-Gloss annotations for each sign added by the researcher. Annotating complete discourses with ID-Glosses is how corpora are created for these languages. For parallel corpora, there is an additional representation established between units in the original source text and the corresponding units in the translation.
Cokely Parallel Corpus development
The original Cokely Parallel Corpus used a project-specific ID-Gloss lexical database. These ID-Glosses were used to annotate the six American Freedom Speeches DVD video translations in ELAN. To create the parallel corpus, the annotations were then exported as text transcriptions to a Microsoft Excel spreadsheet where the transcriptions were divided at the utterance and idea unit levels. Also within the spreadsheet, the English source text was divided at the sentence and idea unit levels. The ASL translation units were then aligned with the corresponding English source text units in the spreadsheet. In the original research project, the spreadsheet was also used to tag, code, and analyze the corpus to answer specific research questions. For detailed procedures of how the Cokely Parallel Corpus was originally created, see this guide and Chapter 3 of Roush, 2018).
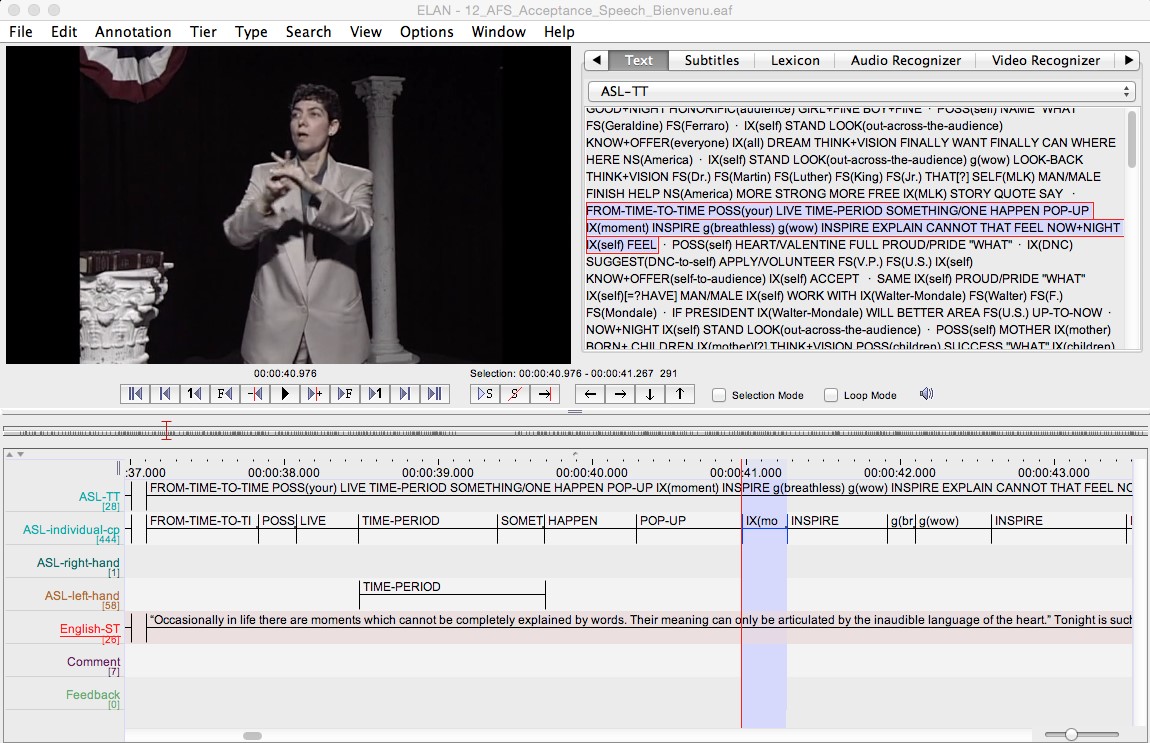
Example of how an ASL translation video is annotated along time-based tiers in ELAN.
Open access to quality parallel corpora
Quality translations of important American political and legal works into American Sign Language are rare. The work of preparing the data such as securing copyright permissions, developing an ID-Gloss lexicon, identifying ASL utterance boundaries, and annotating signs is a painstaking process. Moreover, as with most translations, the original sentences can be split, merged, omitted, added, or reordered by the translator. This requires a sophisticated mapping schema and tools to show the complex correspondences between units in the original text and the translation. These barriers make the development of a parallel corpus a non-trivial task. This is especially true in the case where one or both of the languages do not have a writing system. To allow other researchers to benefit from the fruits of our labor, we are excited to offer this free ASL language resource for use under a Creative Commons BY-NC-SA 4.0 license.
Cokely Parallel Corpus data
To fully use the Cokely Parallel Corpus (CPC) data you will need to download and install the latest version of ELAN (this software application is free). You will also need to have access to spreadsheet or database software such as Microsoft Excel, or Google Sheets. The CPC is organized into separate pages that can be accessed below. Each page contains:
- The streaming video of the ASL translation that gives you a preview of the video file (the video does not contain any English captions or audio)
- The original English excerpt on which the ASL translation is based
- Two versions of the .mp4 video file for download, one Standard Definition, the other High Definition. These video files need to be downloaded in a local directory and be associated as a linked media file with the respective .eaf files from within ELAN
- An ELAN .eaf file that contains primarily the ASL ID-Gloss annotations within marked utterance boundaries. Note, the English source text is only loosely annotated for general reference on a symbolic tier in ELAN since the video itself is in ASL only. The tight alignment between the English source text and ASL translation units is in the respective .xlsx spreadsheet file
- A Microsoft Excel .xlsx file that contains four sheets:
- English source text divided into numbered sentences and idea units
- ASL translation transcription divided into numbered utterances and idea units
- An alignment between the source text and translation idea units represented by adjacent rows
- Identification, coding, and analysis of metaphors in the English source text and ASL translation and how these were handled by the translators (see the Research Guide and Roush, 2018)
- A .docx file that contains the English text excerpt with numbered sentences
- A .pdf file of relevant pages from the American Freedom Speeches Instructor’s Guide that contains the full English text with the translated excerpts highlighted with a gray background. It also contains pages that provide historical and biographical background to the English text
- The American Freedom Speeches parallel corpus design, building, and annotation guidelines (Research Guide)
- The full Cokely Parallel Corpus Excel .xlsx file that combines all the sheets from the .xlsx files from each of the 6 translations
- A .pdf file of the full American Freedom Speeches Instructor’s Guide (permission to reproduce the material in the Guide is granted from Signmedia, Inc., all other rights are reserved)
- Sign Media, Inc. (1994). American freedom speeches (2012 DVD) [Videos containing political speeches and documents translated into American Sign Language]. www.signmedia.com. http://store.signmedia.com/1811.html
- Roush, D., & Schilling, A. (2021). The Dennis Cokely American freedom speeches parallel corpus (1.0) [Dataset]. Eastern Kentucky University Libraries. https://encompass.eku.edu/cokely/
Additional materials
Attribution
In keeping with the terms of the Creative Commons BY-NC-SA 4.0 license, please use both of the following citations on any work resulting from the Cokely Parallel Corpus:-
![I Have a Dream, by Martin Luther King, Jr. : ASL translation by David Hamilton, et al. [HD Video] by SignMedia](https://encompass.eku.edu/cokely_videos/1000/thumbnail.jpg "I Have a Dream, by Martin Luther King, Jr. : ASL translation by David Hamilton, et al. [HD Video] by SignMedia")
I Have a Dream, by Martin Luther King, Jr. : ASL translation by David Hamilton, et al. [HD Video]
SignMedia
An American Sign Language translation of English excerpts taken from Martin Luther King, Jr.'s "I Have a Dream" speech. Translation was prepared by MJ Bienvenu, Patrick Graybill, Dennis Cokely and performed by David Hamilton. This is part of the Cokely Parallel Corpus collection. Additional materials are provided here for corpus-based research.
-
![On Human Rights by Jimmy Carter: ASL translation by Pat Graybill, et al. [HD Video] by SignMedia](https://encompass.eku.edu/cokely_videos/1002/thumbnail.jpg "On Human Rights by Jimmy Carter: ASL translation by Pat Graybill, et al. [HD Video] by SignMedia")
On Human Rights by Jimmy Carter: ASL translation by Pat Graybill, et al. [HD Video]
SignMedia
An American Sign Language translation of English excerpts taken from Jimmy Carter's "On Human Rights" speech. Translation was prepared by MJ Bienvenu, Patrick Graybill, Dennis Cokely and performed by Patrick Graybill. This is part of the Cokely Parallel Corpus collection. Additional materials are provided here for corpus-based research.
-
![Pledge of Allegiance by Francis Bellamy: Two ASL translations by Patrick Graybill, et al. [HD Video] by SignMedia](https://encompass.eku.edu/cokely_videos/1005/thumbnail.jpg "Pledge of Allegiance by Francis Bellamy: Two ASL translations by Patrick Graybill, et al. [HD Video] by SignMedia")
Pledge of Allegiance by Francis Bellamy: Two ASL translations by Patrick Graybill, et al. [HD Video]
SignMedia
Two American Sign Language translation versions of the English "Pledge of Allegiance" text by Francis Bellamy. The translations were prepared by MJ Bienvenu, Patrick Graybill, Dennis Cokely and performed by Patrick Graybill. This is part of the Cokely Parallel Corpus collection. Additional materials are provided here for corpus-based research.
-
![Preamble to the Constitution: ASL translation by Patrick Graybill, et al. [HD Video] by SignMedia](https://encompass.eku.edu/cokely_videos/1001/thumbnail.jpg "Preamble to the Constitution: ASL translation by Patrick Graybill, et al. [HD Video] by SignMedia")
Preamble to the Constitution: ASL translation by Patrick Graybill, et al. [HD Video]
SignMedia
An American Sign Language translation of the English "Preamble to the United States" by The Constitutional Convention Committee on Style. Translation was prepared by MJ Bienvenu, Patrick Graybill, Dennis Cokely and performed by Patrick Graybill. This is part of the Cokely Parallel Corpus collection. Additional materials are provided here for corpus-based research.
-
![Struggle for Justice by Cesar Chavez: ASL translation by Mark Morales, et al. [HD Video] by SignMedia](https://encompass.eku.edu/cokely_videos/1003/thumbnail.jpg "Struggle for Justice by Cesar Chavez: ASL translation by Mark Morales, et al. [HD Video] by SignMedia")
Struggle for Justice by Cesar Chavez: ASL translation by Mark Morales, et al. [HD Video]
SignMedia
An American Sign Language translation of English excerpts taken from Cesar Chavez's "Struggle for Justice" speech. Translation was prepared by MJ Bienvenu, Patrick Graybill, Dennis Cokely and performed by Mark Morales. This is part of the Cokely Parallel Corpus collection. Additional materials are provided here for corpus-based research.
-
![Vice Presidential Nomination Acceptance Speech by Geraldine Ferraro: ASL translation by MJ Bienvenu, et al. [HD Video] by SignMedia](https://encompass.eku.edu/cokely_videos/1004/thumbnail.jpg "Vice Presidential Nomination Acceptance Speech by Geraldine Ferraro: ASL translation by MJ Bienvenu, et al. [HD Video] by SignMedia")
Vice Presidential Nomination Acceptance Speech by Geraldine Ferraro: ASL translation by MJ Bienvenu, et al. [HD Video]
SignMedia
An American Sign Language translation of English excerpts taken from Geraldine Ferraro's "Vice Presidential Nomination Acceptance" speech. Translation was prepared by MJ Bienvenu, Patrick Graybill, Dennis Cokely and performed by MJ Bienvenu. This is part of the Cokely Parallel Corpus collection. Additional materials are provided here for corpus-based research.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}